ML/AI Image Classifier for Skin Cancer Detection

Skin cancer is one of the most active types of cancer in the present decade. As the skin is the body’s largest organ, the point of considering skin cancer as the most common type of cancer among humans is understandable. It is generally classified into two major categories: nonmelanoma (benign)


and melanoma (malignant) skin cancer
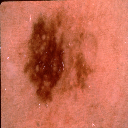
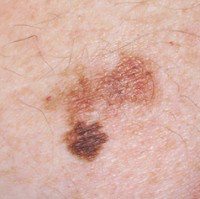
Melanoma type of cancers can only be cured if diagnosed early; otherwise, they spread to other body parts and lead to the victim’s painful death.
Therefore, the critical factor in skin cancer treatment is early diagnosis.
Yet, diagnoses is still a visual process, which relies on the long-winded procedure of clinical screenings, followed by dermoscopic analysis, and then a biopsy and finally a histopathological examination. This process easily takes months and the need for many medical professionals and still is only ~77% accurate.
Current methods using AI and Deep Learning to diagnose lesions show potential to spare time and mitigate errors- saving millions of lives in the long run.
Using TensorFlow library in Python, we can implement an image recognition skin disease classifier that tries to distinguish between benign (nevus and seborrheic keratosis) and malignant (melanoma) skin diseases from only photographic 2D RGB images, as shown above.
Step 1: Installing and Importing Essential Libraries
!pip3 install tensorflow tensorflow_hub matplotlib seaborn numpy pandas sklearn imblearn
Collecting tensorflow Using cached tensorflow-2.8.0-cp39-cp39-win_amd64.whl (438.0 MB) Collecting tensorflow_hub Downloading tensorflow_hub-0.12.0-py2.py3-none-any.whl (108 kB) Requirement already satisfied: matplotlib in c:\users\adrou\anaconda3\lib\site-packages (3.4.3) Requirement already satisfied: seaborn in c:\users\adrou\anaconda3\lib\site-packages (0.11.2) Requirement already satisfied: numpy in c:\users\adrou\anaconda3\lib\site-packages (1.20.3) Requirement already satisfied: pandas in c:\users\adrou\anaconda3\lib\site-packages (1.4.2) Collecting sklearn Downloading sklearn-0.0.tar.gz (1.1 kB) Collecting imblearn Downloading imblearn-0.0-py2.py3-none-any.whl (1.9 kB) Collecting termcolor>=1.1.0 Using cached termcolor-1.1.0-py3-none-any.whl Collecting opt-einsum>=2.3.2 Using cached opt_einsum-3.3.0-py3-none-any.whl (65 kB) Collecting gast>=0.2.1 Using cached gast-0.5.3-py3-none-any.whl (19 kB) Collecting astunparse>=1.6.0 Using cached astunparse-1.6.3-py2.py3-none-any.whl (12 kB) Collecting tensorboard<2.9,>=2.8 Using cached tensorboard-2.8.0-py3-none-any.whl (5.8 MB) Requirement already satisfied: setuptools in c:\users\adrou\anaconda3\lib\site-packages (from tensorflow) (58.0.4) Collecting flatbuffers>=1.12 Using cached flatbuffers-2.0-py2.py3-none-any.whl (26 kB) Requirement already satisfied: typing-extensions>=3.6.6 in c:\users\adrou\anaconda3\lib\site-packages (from tensorflow) (3.10.0.2) Collecting tensorflow-io-gcs-filesystem>=0.23.1 Downloading tensorflow_io_gcs_filesystem-0.25.0-cp39-cp39-win_amd64.whl (1.5 MB) Collecting libclang>=9.0.1 Downloading libclang-14.0.1-py2.py3-none-win_amd64.whl (14.2 MB) Collecting google-pasta>=0.1.1 Using cached google_pasta-0.2.0-py3-none-any.whl (57 kB) Collecting absl-py>=0.4.0 Using cached absl_py-1.0.0-py3-none-any.whl (126 kB) Requirement already satisfied: wrapt>=1.11.0 in c:\users\adrou\anaconda3\lib\site-packages (from tensorflow) (1.12.1) Requirement already satisfied: six>=1.12.0 in c:\users\adrou\anaconda3\lib\site-packages (from tensorflow) (1.16.0) Collecting keras<2.9,>=2.8.0rc0 Using cached keras-2.8.0-py2.py3-none-any.whl (1.4 MB) Collecting tf-estimator-nightly==2.8.0.dev2021122109 Using cached tf_estimator_nightly-2.8.0.dev2021122109-py2.py3-none-any.whl (462 kB) Collecting grpcio<2.0,>=1.24.3 Using cached grpcio-1.44.0-cp39-cp39-win_amd64.whl (3.4 MB) Collecting protobuf>=3.9.2 Downloading protobuf-3.20.1-cp39-cp39-win_amd64.whl (904 kB) Collecting keras-preprocessing>=1.1.1 Using cached Keras_Preprocessing-1.1.2-py2.py3-none-any.whl (42 kB) Requirement already satisfied: h5py>=2.9.0 in c:\users\adrou\anaconda3\lib\site-packages (from tensorflow) (3.2.1) Requirement already satisfied: pillow>=6.2.0 in c:\users\adrou\anaconda3\lib\site-packages (from matplotlib) (8.4.0) Requirement already satisfied: pyparsing>=2.2.1 in c:\users\adrou\anaconda3\lib\site-packages (from matplotlib) (3.0.4) Requirement already satisfied: kiwisolver>=1.0.1 in c:\users\adrou\anaconda3\lib\site-packages (from matplotlib) (1.3.1) Requirement already satisfied: python-dateutil>=2.7 in c:\users\adrou\anaconda3\lib\site-packages (from matplotlib) (2.8.2) Requirement already satisfied: cycler>=0.10 in c:\users\adrou\anaconda3\lib\site-packages (from matplotlib) (0.10.0) Requirement already satisfied: scipy>=1.0 in c:\users\adrou\anaconda3\lib\site-packages (from seaborn) (1.7.1) Requirement already satisfied: pytz>=2020.1 in c:\users\adrou\anaconda3\lib\site-packages (from pandas) (2021.3) Requirement already satisfied: scikit-learn in c:\users\adrou\appdata\roaming\python\python39\site-packages (from sklearn) (1.0.2) Collecting imbalanced-learn Downloading imbalanced_learn-0.9.0-py3-none-any.whl (199 kB) Requirement already satisfied: wheel<1.0,>=0.23.0 in c:\users\adrou\anaconda3\lib\site-packages (from astunparse>=1.6.0->tensorflow) (0.37.0) Requirement already satisfied: werkzeug>=0.11.15 in c:\users\adrou\anaconda3\lib\site-packages (from tensorboard<2.9,>=2.8->tensorflow) (2.0.2) Collecting google-auth<3,>=1.6.3 Downloading google_auth-2.6.6-py2.py3-none-any.whl (156 kB) Collecting tensorboard-plugin-wit>=1.6.0 Using cached tensorboard_plugin_wit-1.8.1-py3-none-any.whl (781 kB) Requirement already satisfied: requests<3,>=2.21.0 in c:\users\adrou\anaconda3\lib\site-packages (from tensorboard<2.9,>=2.8->tensorflow) (2.26.0) Collecting markdown>=2.6.8 Using cached Markdown-3.3.6-py3-none-any.whl (97 kB) Collecting tensorboard-data-server<0.7.0,>=0.6.0 Using cached tensorboard_data_server-0.6.1-py3-none-any.whl (2.4 kB) Collecting google-auth-oauthlib<0.5,>=0.4.1 Using cached google_auth_oauthlib-0.4.6-py2.py3-none-any.whl (18 kB) Collecting pyasn1-modules>=0.2.1 Using cached pyasn1_modules-0.2.8-py2.py3-none-any.whl (155 kB) Collecting cachetools<6.0,>=2.0.0 Using cached cachetools-5.0.0-py3-none-any.whl (9.1 kB) Collecting rsa<5,>=3.1.4 Using cached rsa-4.8-py3-none-any.whl (39 kB) Collecting requests-oauthlib>=0.7.0 Using cached requests_oauthlib-1.3.1-py2.py3-none-any.whl (23 kB) Requirement already satisfied: importlib-metadata>=4.4 in c:\users\adrou\anaconda3\lib\site-packages (from markdown>=2.6.8->tensorboard<2.9,>=2.8->tensorflow) (4.8.1) Requirement already satisfied: zipp>=0.5 in c:\users\adrou\anaconda3\lib\site-packages (from importlib-metadata>=4.4->markdown>=2.6.8->tensorboard<2.9,>=2.8->tensorflow) (3.6.0) Collecting pyasn1<0.5.0,>=0.4.6 Using cached pyasn1-0.4.8-py2.py3-none-any.whl (77 kB) Requirement already satisfied: certifi>=2017.4.17 in c:\users\adrou\anaconda3\lib\site-packages (from requests<3,>=2.21.0->tensorboard<2.9,>=2.8->tensorflow) (2021.10.8) Requirement already satisfied: idna<4,>=2.5 in c:\users\adrou\anaconda3\lib\site-packages (from requests<3,>=2.21.0->tensorboard<2.9,>=2.8->tensorflow) (3.2) Requirement already satisfied: urllib3<1.27,>=1.21.1 in c:\users\adrou\anaconda3\lib\site-packages (from requests<3,>=2.21.0->tensorboard<2.9,>=2.8->tensorflow) (1.26.7) Requirement already satisfied: charset-normalizer~=2.0.0 in c:\users\adrou\anaconda3\lib\site-packages (from requests<3,>=2.21.0->tensorboard<2.9,>=2.8->tensorflow) (2.0.4) Collecting oauthlib>=3.0.0 Using cached oauthlib-3.2.0-py3-none-any.whl (151 kB) Requirement already satisfied: threadpoolctl>=2.0.0 in c:\users\adrou\anaconda3\lib\site-packages (from imbalanced-learn->imblearn) (2.2.0) Requirement already satisfied: joblib>=0.11 in c:\users\adrou\anaconda3\lib\site-packages (from imbalanced-learn->imblearn) (1.1.0) Building wheels for collected packages: sklearn Building wheel for sklearn (setup.py): started Building wheel for sklearn (setup.py): finished with status 'done' Created wheel for sklearn: filename=sklearn-0.0-py2.py3-none-any.whl size=1309 sha256=a5495a96301ac8f85d594938a22b291a5552f52313b34a9efecf972d691f944a Stored in directory: c:\users\adrou\appdata\local\pip\cache\wheels\e4\7b\98\b6466d71b8d738a0c547008b9eb39bf8676d1ff6ca4b22af1c Successfully built sklearn Installing collected packages: pyasn1, rsa, pyasn1-modules, oauthlib, cachetools, requests-oauthlib, google-auth, tensorboard-plugin-wit, tensorboard-data-server, protobuf, markdown, grpcio, google-auth-oauthlib, absl-py, tf-estimator-nightly, termcolor, tensorflow-io-gcs-filesystem, tensorboard, opt-einsum, libclang, keras-preprocessing, keras, imbalanced-learn, google-pasta, gast, flatbuffers, astunparse, tensorflow-hub, tensorflow, sklearn, imblearn Successfully installed absl-py-1.0.0 astunparse-1.6.3 cachetools-5.0.0 flatbuffers-2.0 gast-0.5.3 google-auth-2.6.6 google-auth-oauthlib-0.4.6 google-pasta-0.2.0 grpcio-1.44.0 imbalanced-learn-0.9.0 imblearn-0.0 keras-2.8.0 keras-preprocessing-1.1.2 libclang-14.0.1 markdown-3.3.6 oauthlib-3.2.0 opt-einsum-3.3.0 protobuf-3.20.1 pyasn1-0.4.8 pyasn1-modules-0.2.8 requests-oauthlib-1.3.1 rsa-4.8 sklearn-0.0 tensorboard-2.8.0 tensorboard-data-server-0.6.1 tensorboard-plugin-wit-1.8.1 tensorflow-2.8.0 tensorflow-hub-0.12.0 tensorflow-io-gcs-filesystem-0.25.0 termcolor-1.1.0 tf-estimator-nightly-2.8.0.dev2021122109
#import libraries
import tensorflow as tf
import tensorflow_hub as hub
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
import seaborn as sns
from tensorflow.keras.utils import get_file
from sklearn.metrics import roc_curve, auc, confusion_matrix
from imblearn.metrics import sensitivity_score, specificity_score
import os
import glob
import zipfile
import random
# to get consistent results after multiple runs
tf.random.set_seed(7)
np.random.seed(7)
random.seed(7)
# 0 for benign, 1 for malignant
class_names = ["benign", "malignant"]
Step 2: Reading and Processing Data
We'll be using only a small part of ISIC archive dataset, the below function downloads and extract the dataset into a new
data folder:def download_and_extract_dataset():
# dataset from https://github.com/udacity/dermatologist-ai
# 5.3GB
train_url = "https://s3-us-west-1.amazonaws.com/udacity-dlnfd/datasets/skin-cancer/train.zip"
# 824.5MB
valid_url = "https://s3-us-west-1.amazonaws.com/udacity-dlnfd/datasets/skin-cancer/valid.zip"
# 5.1GB
test_url = "https://s3-us-west-1.amazonaws.com/udacity-dlnfd/datasets/skin-cancer/test.zip"
for i, download_link in enumerate([valid_url, train_url, test_url]):
temp_file = f"temp{i}.zip"
data_dir = get_file(origin=download_link, fname=os.path.join(os.getcwd(), temp_file))
print("Extracting", download_link)
with zipfile.ZipFile(data_dir, "r") as z:
z.extractall("data")
# remove the temp file
os.remove(temp_file)
# call the above function to download the dataset
download_and_extract_dataset()
Downloading data from https://s3-us-west-1.amazonaws.com/udacity-dlnfd/datasets/skin-cancer/valid.zip 864542720/864538487 [==============================] - 66s 0us/step 864550912/864538487 [==============================] - 66s 0us/step Extracting https://s3-us-west-1.amazonaws.com/udacity-dlnfd/datasets/skin-cancer/valid.zip Downloading data from https://s3-us-west-1.amazonaws.com/udacity-dlnfd/datasets/skin-cancer/train.zip 5736562688/5736557430 [==============================] - 381s 0us/step 5736570880/5736557430 [==============================] - 381s 0us/step Extracting https://s3-us-west-1.amazonaws.com/udacity-dlnfd/datasets/skin-cancer/train.zip Downloading data from https://s3-us-west-1.amazonaws.com/udacity-dlnfd/datasets/skin-cancer/test.zip 5528641536/5528640507 [==============================] - 389s 0us/step 5528649728/5528640507 [==============================] - 389s 0us/step Extracting https://s3-us-west-1.amazonaws.com/udacity-dlnfd/datasets/skin-cancer/test.zip
# preparing data
# generate CSV metadata file to read img paths and labels from it
def generate_csv(folder, label2int):
folder_name = os.path.basename(folder)
labels = list(label2int)
# generate CSV file
df = pd.DataFrame(columns=["filepath", "label"])
i = 0
for label in labels:
print("Reading", os.path.join(folder, label, "*"))
for filepath in glob.glob(os.path.join(folder, label, "*")):
df.loc[i] = [filepath, label2int[label]]
i += 1
output_file = f"{folder_name}.csv"
print("Saving", output_file)
df.to_csv(output_file)
# generate CSV files for all data portions, labeling nevus and seborrheic keratosis
# as 0 (benign), and melanoma as 1 (malignant)
# you should replace "data" path to your extracted dataset path
# don't replace if you used download_and_extract_dataset() function
generate_csv("data/train", {"nevus": 0, "seborrheic_keratosis": 0, "melanoma": 1})
generate_csv("data/valid", {"nevus": 0, "seborrheic_keratosis": 0, "melanoma": 1})
generate_csv("data/test", {"nevus": 0, "seborrheic_keratosis": 0, "melanoma": 1})
Reading data/train\nevus\* Reading data/train\seborrheic_keratosis\* Reading data/train\melanoma\* Saving train.csv Reading data/valid\nevus\* Reading data/valid\seborrheic_keratosis\* Reading data/valid\melanoma\* Saving valid.csv Reading data/test\nevus\* Reading data/test\seborrheic_keratosis\* Reading data/test\melanoma\* Saving test.csv
# loading data
train_metadata_filename = "train.csv"
valid_metadata_filename = "valid.csv"
# load CSV files as DataFrames
df_train = pd.read_csv(train_metadata_filename)
df_valid = pd.read_csv(valid_metadata_filename)
n_training_samples = len(df_train)
n_validation_samples = len(df_valid)
print("Number of training samples:", n_training_samples)
print("Number of validation samples:", n_validation_samples)
train_ds = tf.data.Dataset.from_tensor_slices((df_train["filepath"], df_train["label"]))
valid_ds = tf.data.Dataset.from_tensor_slices((df_valid["filepath"], df_valid["label"]))
Number of training samples: 2000 Number of validation samples: 150
# preprocess data
def decode_img(img):
# convert the compressed string to a 3D uint8 tensor
img = tf.image.decode_jpeg(img, channels=3)
# Use `convert_image_dtype` to convert to floats in the [0,1] range.
img = tf.image.convert_image_dtype(img, tf.float32)
# resize the image to the desired size.
return tf.image.resize(img, [299, 299])
def process_path(filepath, label):
# load the raw data from the file as a string
img = tf.io.read_file(filepath)
img = decode_img(img)
return img, label
valid_ds = valid_ds.map(process_path)
train_ds = train_ds.map(process_path)
# test_ds = test_ds
for image, label in train_ds.take(1):
print("Image shape:", image.shape)
print("Label:", label.numpy())
Image shape: (299, 299, 3) Label: 0
The input is an image (which is basically a matrix) having dimension (299x299x3) while the output will be an integer – 0 for benign and 1 for malignant.# training parameters
batch_size = 64
optimizer = "rmsprop"
def prepare_for_training(ds, cache=True, batch_size=64, shuffle_buffer_size=1000):
if cache:
if isinstance(cache, str):
ds = ds.cache(cache)
else:
ds = ds.cache()
# shuffle the dataset
ds = ds.shuffle(buffer_size=shuffle_buffer_size)
# Repeat forever
ds = ds.repeat()
# split to batches
ds = ds.batch(batch_size)
# `prefetch` lets the dataset fetch batches in the background while the model
# is training.
ds = ds.prefetch(buffer_size=tf.data.experimental.AUTOTUNE)
return ds
valid_ds = prepare_for_training(valid_ds, batch_size=batch_size, cache="valid-cached-data")
train_ds = prepare_for_training(train_ds, batch_size=batch_size, cache="train-cached-data")
batch = next(iter(valid_ds))
def show_batch(batch):
plt.figure(figsize=(12,12))
for n in range(25):
ax = plt.subplot(5,5,n+1)
plt.imshow(batch[0][n])
plt.title(class_names[batch[1][n].numpy()].title())
plt.axis('off')
show_batch(batch)
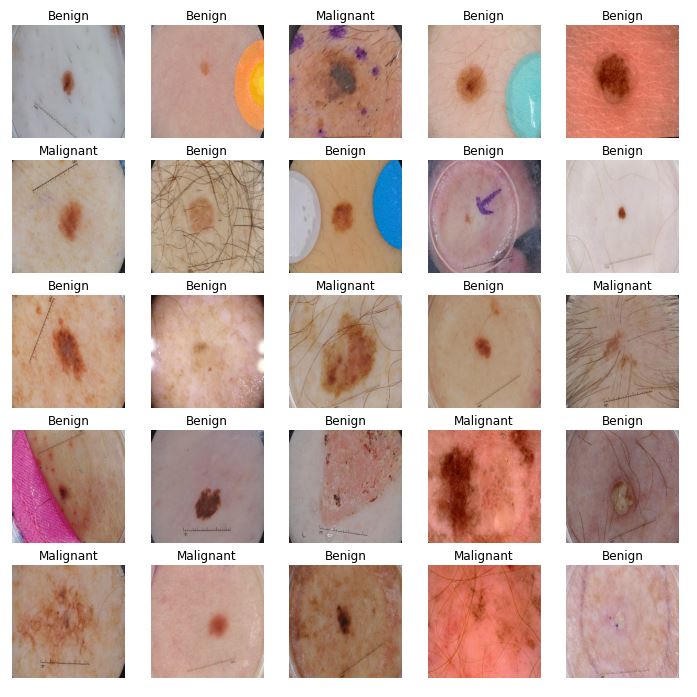
That is a part of our training image dataset. Let's start building the model. We'll be using transfer learning with TensorFlow Hub library to download and load the InceptionV3 architecture along with its ImageNet pre-trained weights.
Step 3: Building the Model
# building the model
# InceptionV3 model & pre-trained weights
module_url = "https://tfhub.dev/google/tf2-preview/inception_v3/feature_vector/4"
m = tf.keras.Sequential([
hub.KerasLayer(module_url, output_shape=[2048], trainable=False),
tf.keras.layers.Dense(1, activation="sigmoid")
])
m.build([None, 299, 299, 3])
m.compile(loss="binary_crossentropy", optimizer=optimizer, metrics=["accuracy"])
m.summary()
Model: "sequential"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
keras_layer (KerasLayer) (None, 2048) 21802784
dense (Dense) (None, 1) 2049
=================================================================
Total params: 21,804,833
Trainable params: 2,049
Non-trainable params: 21,802,784
_________________________________________________________________
model_name = f"benign-vs-malignant_{batch_size}_{optimizer}"
tensorboard = tf.keras.callbacks.TensorBoard(log_dir=os.path.join("logs", model_name))
# saves model checkpoint whenever we reach better weights
modelcheckpoint = tf.keras.callbacks.ModelCheckpoint(model_name + "_{val_loss:.3f}.h5", save_best_only=True, verbose=1)
history = m.fit(train_ds, validation_data=valid_ds,
steps_per_epoch=n_training_samples // batch_size,
validation_steps=n_validation_samples // batch_size, verbose=1, epochs=100,
callbacks=[tensorboard, modelcheckpoint])Epoch 1/100 31/31 [==============================] - ETA: 0s - loss: 0.4600 - accuracy: 0.7707 Epoch 1: val_loss improved from inf to 0.57842, saving model to benign-vs-malignant_64_rmsprop_0.578.h5 31/31 [==============================] - 123s 3s/step - loss: 0.4600 - accuracy: 0.7707 - val_loss: 0.5784 - val_accuracy: 0.7734 Epoch 2/100 31/31 [==============================] - ETA: 0s - loss: 0.4077 - accuracy: 0.8070 Epoch 2: val_loss improved from 0.57842 to 0.50465, saving model to benign-vs-malignant_64_rmsprop_0.505.h5 31/31 [==============================] - 82s 3s/step - loss: 0.4077 - accuracy: 0.8070 - val_loss: 0.5047 - val_accuracy: 0.7969 Epoch 3/100 31/31 [==============================] - ETA: 0s - loss: 0.3871 - accuracy: 0.8251 Epoch 3: val_loss improved from 0.50465 to 0.47657, saving model to benign-vs-malignant_64_rmsprop_0.477.h5 31/31 [==============================] - 80s 3s/step - loss: 0.3871 - accuracy: 0.8251 - val_loss: 0.4766 - val_accuracy: 0.8203 Epoch 4/100 31/31 [==============================] - ETA: 0s - loss: 0.3714 - accuracy: 0.8261 Epoch 4: val_loss did not improve from 0.47657 31/31 [==============================] - 79s 3s/step - loss: 0.3714 - accuracy: 0.8261 - val_loss: 0.4893 - val_accuracy: 0.7812 Epoch 5/100 31/31 [==============================] - ETA: 0s - loss: 0.3565 - accuracy: 0.8322 Epoch 5: val_loss improved from 0.47657 to 0.45809, saving model to benign-vs-malignant_64_rmsprop_0.458.h5 31/31 [==============================] - 76s 2s/step - loss: 0.3565 - accuracy: 0.8322 - val_loss: 0.4581 - val_accuracy: 0.7891 Epoch 6/100 31/31 [==============================] - ETA: 0s - loss: 0.3497 - accuracy: 0.8402 Epoch 6: val_loss did not improve from 0.45809 31/31 [==============================] - 72s 2s/step - loss: 0.3497 - accuracy: 0.8402 - val_loss: 0.4607 - val_accuracy: 0.7969 Epoch 7/100 31/31 [==============================] - ETA: 0s - loss: 0.3469 - accuracy: 0.8407 Epoch 7: val_loss improved from 0.45809 to 0.44589, saving model to benign-vs-malignant_64_rmsprop_0.446.h5 31/31 [==============================] - 72s 2s/step - loss: 0.3469 - accuracy: 0.8407 - val_loss: 0.4459 - val_accuracy: 0.7969 Epoch 8/100 31/31 [==============================] - ETA: 0s - loss: 0.3390 - accuracy: 0.8422 Epoch 8: val_loss improved from 0.44589 to 0.43190, saving model to benign-vs-malignant_64_rmsprop_0.432.h5 31/31 [==============================] - 71s 2s/step - loss: 0.3390 - accuracy: 0.8422 - val_loss: 0.4319 - val_accuracy: 0.8125 Epoch 9/100 31/31 [==============================] - ETA: 0s - loss: 0.3491 - accuracy: 0.8417 Epoch 9: val_loss did not improve from 0.43190 31/31 [==============================] - 71s 2s/step - loss: 0.3491 - accuracy: 0.8417 - val_loss: 0.4413 - val_accuracy: 0.8047 Epoch 10/100 31/31 [==============================] - ETA: 0s - loss: 0.3164 - accuracy: 0.8639 Epoch 10: val_loss did not improve from 0.43190 31/31 [==============================] - 71s 2s/step - loss: 0.3164 - accuracy: 0.8639 - val_loss: 0.4825 - val_accuracy: 0.7

Step 4: Model Evaluation
# evaluation
# load testing set
test_metadata_filename = "test.csv"
df_test = pd.read_csv(test_metadata_filename)
n_testing_samples = len(df_test)
print("Number of testing samples:", n_testing_samples)
test_ds = tf.data.Dataset.from_tensor_slices((df_test["filepath"], df_test["label"]))
def prepare_for_testing(ds, cache=True, shuffle_buffer_size=1000):
if cache:
if isinstance(cache, str):
ds = ds.cache(cache)
else:
ds = ds.cache()
ds = ds.shuffle(buffer_size=shuffle_buffer_size)
return ds
test_ds = test_ds.map(process_path)
test_ds = prepare_for_testing(test_ds, cache="test-cached-data")Number of testing samples: 600# convert testing set to numpy array to fit in memory (don't do that when testing # set is too large) y_test = np.zeros((n_testing_samples,)) X_test = np.zeros((n_testing_samples, 299, 299, 3)) for i, (img, label) in enumerate(test_ds.take(n_testing_samples)): # print(img.shape, label.shape) X_test[i] = img y_test[i] = label.numpy() print("y_test.shape:", y_test.shape)
y_test.shape: (600,)
# load the weights with the least loss
m.load_weights("Yourpath/benign-vs-malignant_64_rmsprop_0.371.h5")
Evaluating the model... Loss: 0.45362651348114014 Accuracy: 0.7983333468437195
def get_predictions(threshold=None):
"""
Returns predictions for binary classification given `threshold`
For instance, if threshold is 0.3, then it'll output 1 (malignant) for that sample if
the probability of 1 is 30% or more (instead of 50%)
"""
y_pred = m.predict(X_test)
if not threshold:
threshold = 0.5
result = np.zeros((n_testing_samples,))
for i in range(n_testing_samples):
# test melanoma probability
if y_pred[i][0] >= threshold:
result[i] = 1
# else, it's 0 (benign)
return result
threshold = 0.23
# get predictions with 23% threshold
# which means if the model is 23% sure or more that is malignant,
# it's assigned as malignant, otherwise it's benign
y_pred = get_predictions(threshold)
def plot_confusion_matrix(y_test, y_pred):
cmn = confusion_matrix(y_test, y_pred)
# Normalise
cmn = cmn.astype('float') / cmn.sum(axis=1)[:, np.newaxis]
# print it
print(cmn)
fig, ax = plt.subplots(figsize=(10,10))
sns.heatmap(cmn, annot=True, fmt='.2f',
xticklabels=[f"pred_{c}" for c in class_names],
yticklabels=[f"true_{c}" for c in class_names],
cmap="Blues"
)
plt.ylabel('Actual')
plt.xlabel('Predicted')
# plot the resulting confusion matrix
plt.show()
plot_confusion_matrix(y_test, y_pred)

[[0.63768116 0.36231884] [0.32478632 0.67521368]]
sensitivity = sensitivity_score(y_test, y_pred)
specificity = specificity_score(y_test, y_pred)
print("Melanoma Sensitivity:", sensitivity)
print("Melanoma Specificity:", specificity)Melanoma Sensitivity: 0.6752136752136753 Melanoma Specificity: 0.6376811594202898
def plot_roc_auc(y_true, y_pred):
"""
This function plots the ROC curves and provides the scores.
"""
# prepare for figure
plt.figure()
fpr, tpr, _ = roc_curve(y_true, y_pred)
# obtain ROC AUC
roc_auc = auc(fpr, tpr)
# print score
print(f"ROC AUC: {roc_auc:.3f}")
# plot ROC curve
plt.plot(fpr, tpr, color="blue", lw=2,
label='ROC curve (area = {f:.2f})'.format(d=1, f=roc_auc))
plt.xlim([0.0, 1.0])
plt.ylim([0.0, 1.05])
plt.xlabel('False Positive Rate')
plt.ylabel('True Positive Rate')
plt.title('ROC curves')
plt.legend(loc="lower right")
plt.show()
plot_roc_auc(y_test, y_pred)
ROC AUC: 0.656
plt.hist(y_test)


plt.hist(y_pred)
Thus, the sensitivity (i.e. the probability of a positive test given that the patient has the desease) is 67%, whereas the specificity (i.e. the probability of a negative test given that the patient is well) is 63% for the threshold=0.23. The Area Under Curve ROC (ROC AUC) is 0.66 an area of 1 means the ideal model.
We can improve the model by increasing the number of training samples. We can also tweak the hyperparameters such as the threshold we set earlier, and see if we can get better sensitivity and specificity scores.
INFOGRAPHIC



Comments
Post a Comment